
Если коротко
Поиск задаёт пул источников, из которого нейросеть выбирает, но почти не определяет ни их очерёдность, ни содержание ответа. Поиск решает, кого ИИ возьмет в источники, но не влияет на порядок ответа. Примерно две трети процитированных сайтов берутся с первой страницы выдачи. При этом первая строчка Яндекса становится ведущим источником лишь в одном случае из шести, а едва ли не половина ссылок уходит на вторую страницу и глубже.
С чего начать: о чём вообще исследование
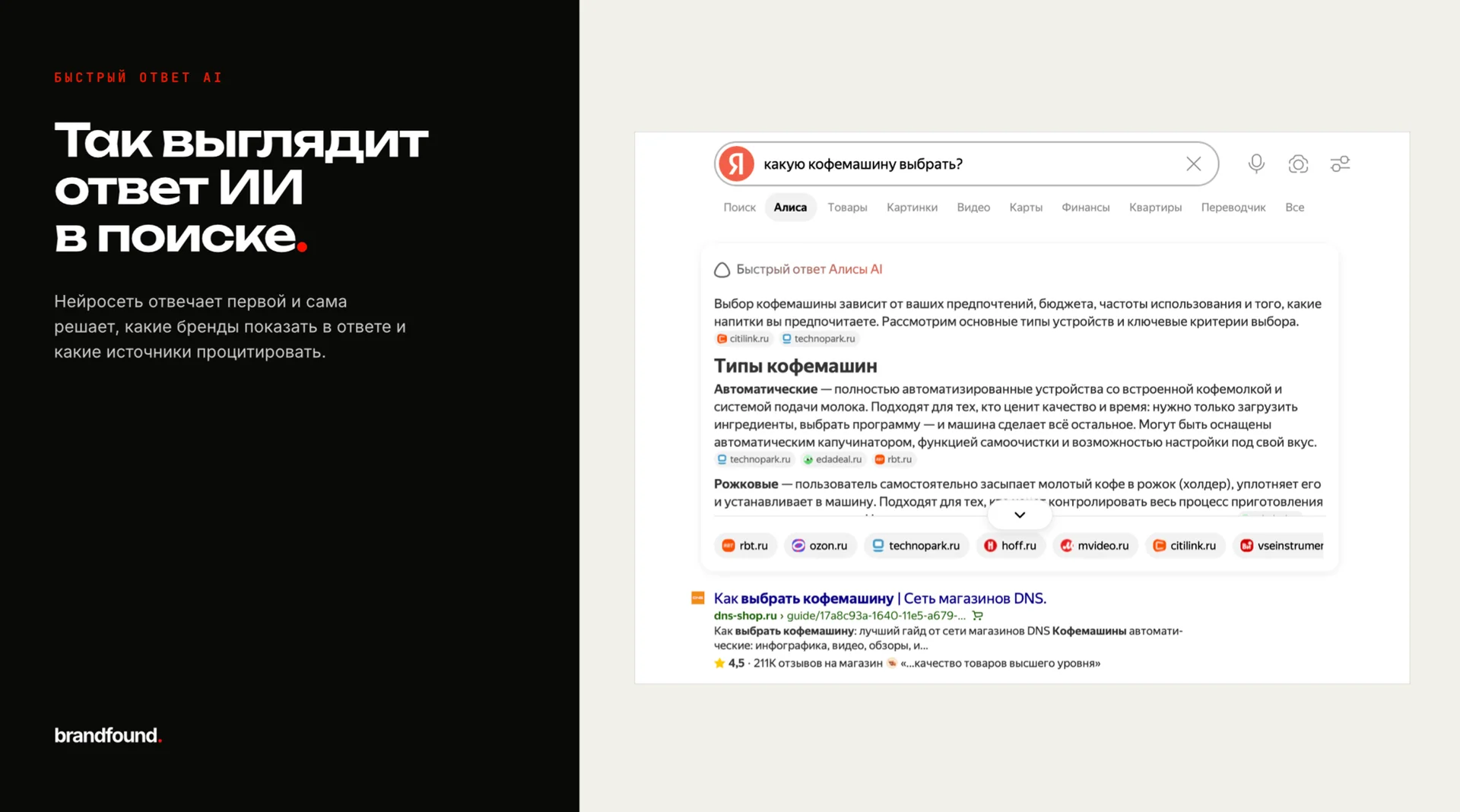
К каждому ответу нейросети прилагаются источники, т.е. сайты, которые она использует. Одни вшиты прямо в текст в виде сносок-цифр, другие просто перечислены списком под ответом.
Параллельно по тому же запросу существует обычная выдача Яндекса: перечень сайтов на первой странице.
Весь вопрос сводится к тому, насколько эти два списка пересекаются: переходит ли позиция в поиске в цитирование у нейросети.
Первая страница это пропуск в ответ, но не более
Ключевой тезис о SEO как канале для GEO: топ поиска заметно увеличивает шанс цитирования, однако это вероятность, а не гарантия.
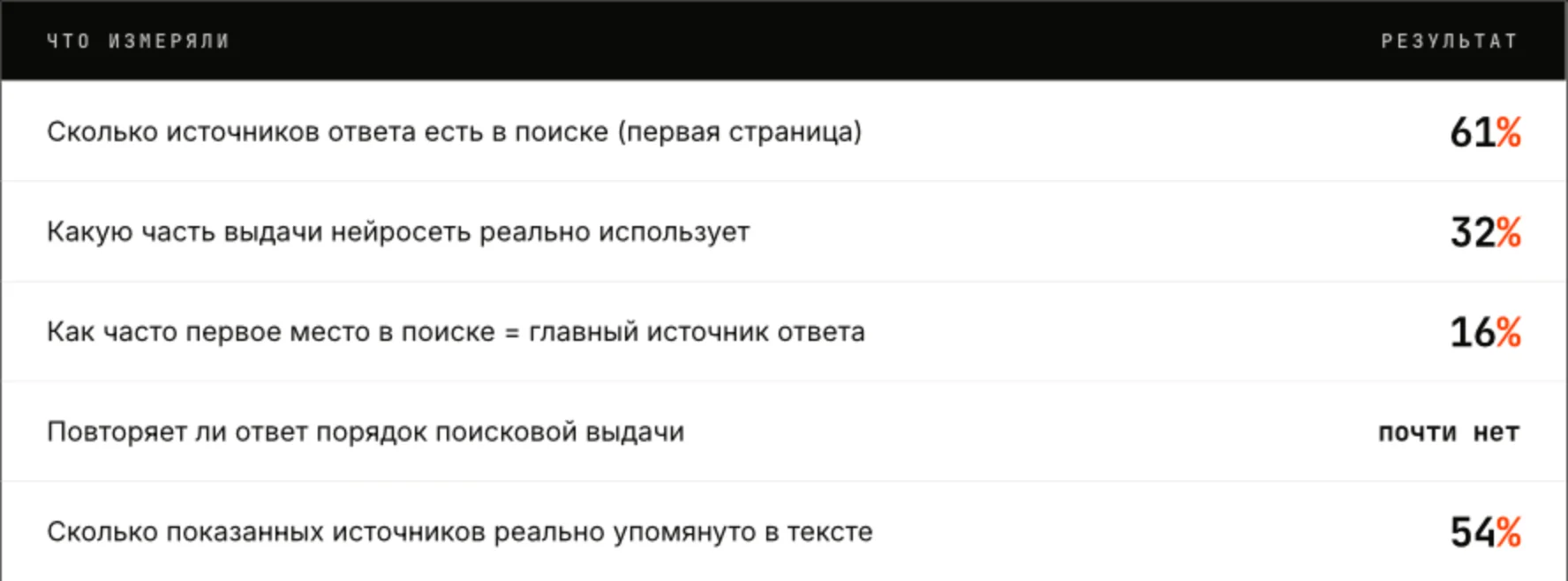
Чем выше сайт в выдаче, тем чаще нейросеть берёт его в источники, и заметно чаще, чем при случайном выборе. Но верхушкой она почти никогда не ограничивается. Ведущий источник, как правило, наверху (в 86% ответов он входит в поисковую тройку), а вот остальные ссылки собираются вглубь: почти половина из них стоит в поиске ниже пятой строчки.
Иначе говоря, попасть в ответ ИИ без топа сложно, присутствие в верхушке даёт кратный рост шансов, но «выиграть выдачу» и «возглавить ответ» это разные задачи.
Первое место в поиске переоценено
Привычная установка «нам нужна первая позиция» в мире нейросетей работает слабо. Посмотрим, что происходит с ведущим источником сайтом, на который Алиса ссылается в первую очередь.

В каждом четвёртом ответе нейросеть стартует с сайта, которого обычная выдача вообще не показывает на первой странице. А абсолютный лидер Яндекса становится голосом Алисы только в 16% случаев.
Очерёдность выдачи в ответ не переносится
Ещё одно заблуждение: будто нейросеть просто пересказывает поиск сверху вниз. На деле порядок почти не воспроизводится, у 39% запросов последовательность источников в ответе оказывается прямо противоположной поисковой.
Работает лишь один механизм: если ответ открывается тем же сайтом, что и первая строчка поиска, дальнейшая очерёдность тоже заметно ближе к выдаче. Но стоит ведущему источнику не совпасть с лидером поиска и связь с порядком пропадает полностью. Вывод: на входе нейросеть тяготеет к верхним сайтам, а внутри ответа расставляет их по смыслу, а не по позициям в Яндексе.
Парадокс: чем короче ответ, тем сильнее зависимость от SEO
Неожиданный, но устойчивый эффект: совпадение с поиском определяется не качеством выдачи, а тем, сколько источников требуется самому ответу.
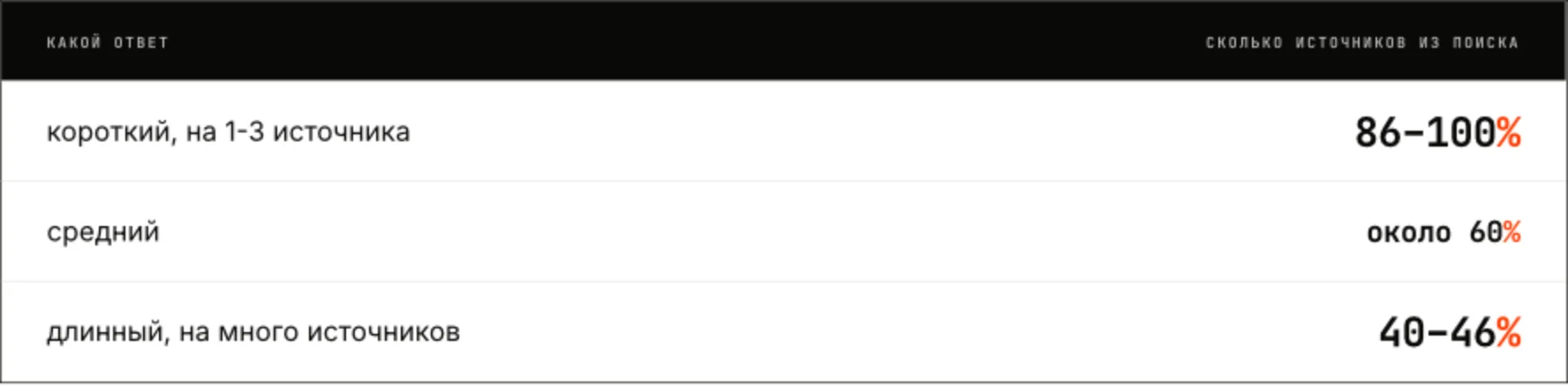
Чем больше ссылок собирает нейросеть и чем развёрнутее текст, тем меньше в нём доля сайтов из топа: для длинных ответов она подтягивает источники со второй страницы.
Поэтому случаи 100% совпадения (каждый шестой ответ), это не образцовая выдача, а короткие нишевые ответы, которым легко уложиться в первую страницу. Для брендов это значит, что в простых коротких темах исход решает топ поиска, а в сложных развёрнутых нейросеть всё равно уйдёт глубже, и одной первой страницы не хватит.
Ответ ИИ это не пересказ первой страницы
Алиса отбирает жёстко: из примерно 12 сайтов первой страницы она оставляет около четырёх, а оставшиеся две трети игнорирует.
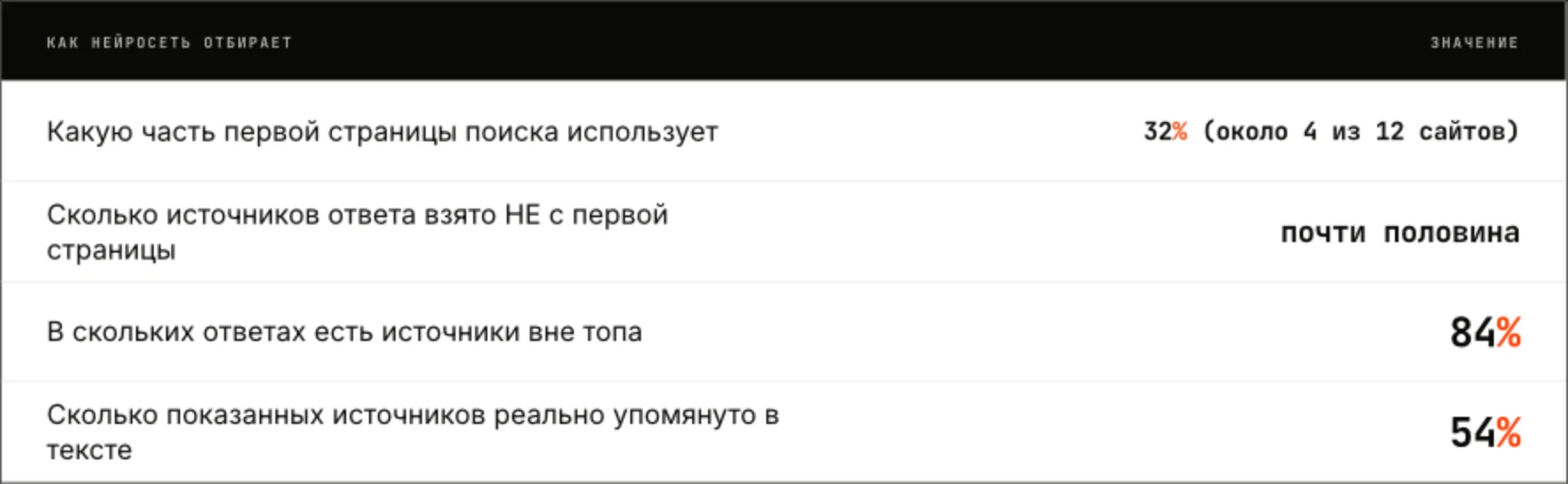
И здесь важна деталь про два списка источников. То, что выведено списком под ответом, скорее витрина, чем полноценная библиография. В сам текст попадает лишь около половины этих сайтов. А связаны с поиском сильнее как раз упоминания в теле ответа, а не нижняя витрина. Прослеживается и ещё одна закономерность: чем длиннее ответ, тем активнее нейросеть использует найденное. Короткий ответ задействует около 42% своего списка, а длинный порядка 66%. Развёрнутые ответы не просто содержат больше ссылок, они и глубже опираются на поиск.
Сила связи зависит от ниши
В среднем, поиск влияет везде, но разброс по темам большой.
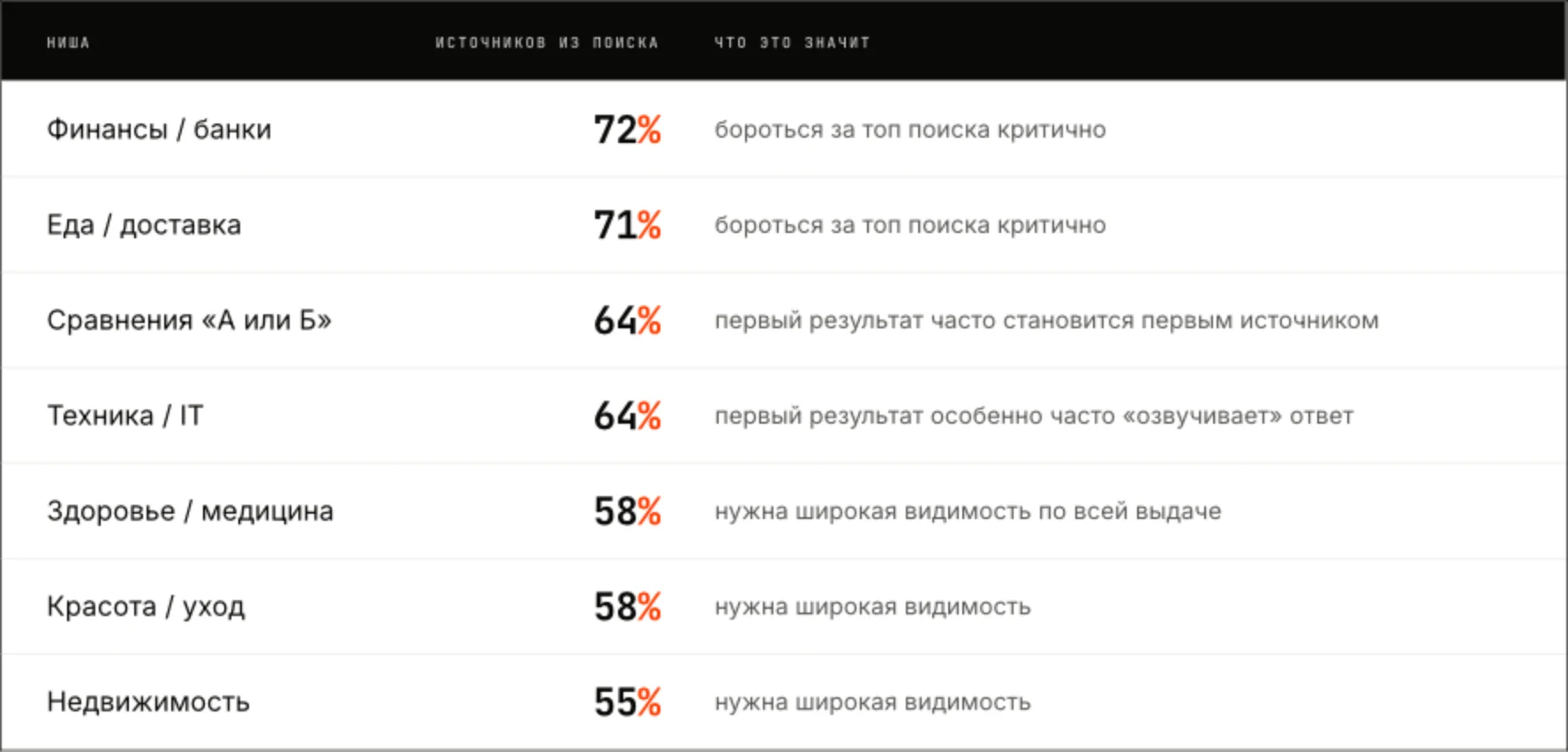
- В финансах и еде ответы короткие и однозначные, источников немного: попал в верхние позиции, значит почти наверняка попал в ответ.
- В здоровье и красоте источников больше, и нейросеть активнее обращается к материалам за пределами первых строчек. Одного присутствия в топе мало, нужна представленность по всей выдаче.
- В технике же особенно часто в ответ попадают специализированные справочные ресурсы: инструкции, техническая документация, каталоги характеристик, сайты с чётко структурированной информацией.
Один и тот же запрос даёт разные ответы
Это критично для любых замеров: ответ нейросети нестабилен. В нашем массиве один и тот же запрос мог давать результаты, где доля источников из поиска расходилась почти на 48 процентных пунктов.
Зато на больших выборках картина устойчива: средние за апрель, май и июнь практически совпадают.
Отсюда вывод: судить о видимости бренда по одному ответу бессмысленно, корректные выводы возможны только на серии замеров. Именно поэтому исследование стоит на 10 000 ответах, а не на десятке отдельных примеров.
Что это значит для GEO-стратегии
-
Топ Яндекса остаётся главным рычагом влияния на ответы нейросети: присутствие в выдаче поднимает шанс попасть в ответ в 2–2,6 раза, так что SEO и GEO не конкуренты, а части одной воронки.
-
При этом переоценивать первое место не стоит, ведущим источником ответа оно становится лишь в 16% случаев.
-
Подход стоит подбирать под тематику. Для финансов, еды и сравнительных запросов ключевую роль играют верхние позиции; для здоровья, красоты и техники важнее широкое присутствие по всей выдаче.
-
В сложных темах решает глубина покрытия: развёрнутые ответы нередко берут источники со второй страницы, поэтому быть представленным только в топе недостаточно.
-
И ещё два принципа. Цель это не просто попасть в список источников, а добиться упоминания в тексте ответа: именно это более сильный сигнал видимости.
-
А любые оценки из-за высокой вариативности ответов нужно строить на средних значениях по серии запросов, а не на разовых проверках.
Как проводилось исследование
Мы проанализировали 10 000 сохранённых ответов нейросети Яндекса за период с апреля по июнь 2026 года; выборка охватила почти 9 000 уникальных запросов.
Для каждого ответа мы собирали два набора данных: источники, на которые ссылалась нейросеть, и результаты первой страницы обычной поисковой выдачи Яндекса по тому же запросу. Затем сравнивали эти наборы по доменам сайтов и смотрели, насколько часто они пересекаются и какие позиции занимают в поиске. Все показатели рассчитаны по всей совокупности данных, что сглаживает нестабильность отдельных ответов.
Исследование подготовлено командой brandfound: мы отслеживаем видимость брендов в ответах нейросетей.


