
Контент пишется на ваших данных, а не на пустом месте
 Обычные генераторы текста работают по промту. Вы даёте нейросети десяток предложений контекста и просите написать статью. На выходе получаете аккуратные вариации одного и того же по шаблону, без опоры на то, что реально происходит с вашим брендом в нейросетях.
Обычные генераторы текста работают по промту. Вы даёте нейросети десяток предложений контекста и просите написать статью. На выходе получаете аккуратные вариации одного и того же по шаблону, без опоры на то, что реально происходит с вашим брендом в нейросетях.
Фабрика устроена иначе. Она пишет не на вымышленных идеях, а на основе вашей же аналитики, и связана с сервисом напрямую. Поэтому материал получается ровно про то, что нужно бренду прямо сейчас, а не «ещё одна статья вообще про вас». В контекст каждой статьи подгружаются метрики, содержимое статей конкурентов из вашей RAG-базы, история поведения нейросетей по этой теме, тональность, источники с их уровнем доверия. Получается не просто красивый текст, а контент, собранный из того, что нейросети в вашей нише уже любят цитировать.
Простая аналогия, которую мы используем сами: можно написать статью на 10 входных предложениях, а можно на 1 000. У фабрики на входе кратно больше данных, поэтому на выходе результат работает.
Канбан-доска: путь карточки от «Идеи» до «Готово»
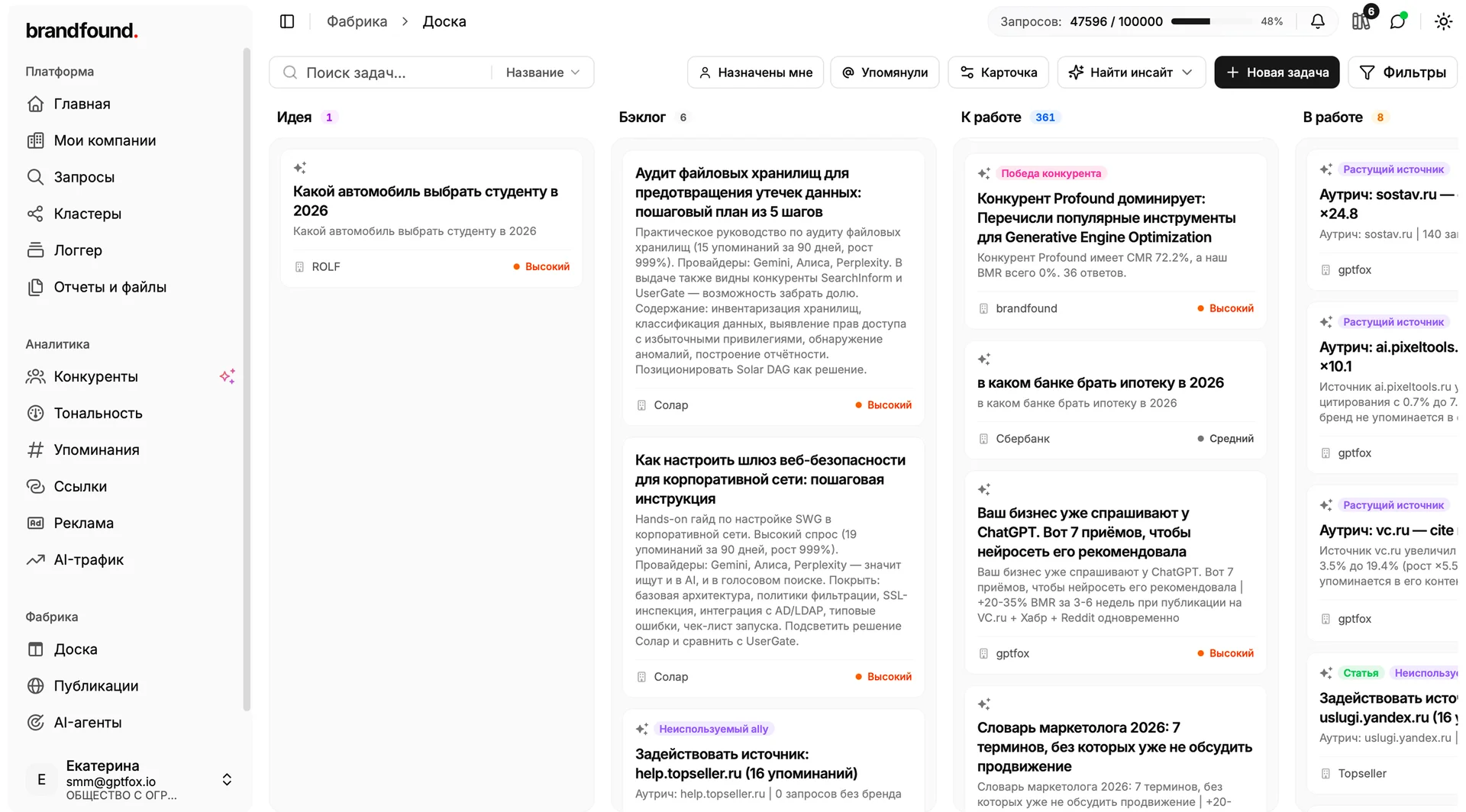
В основе фабрики канбан-доска, знакомая всем, кто работал в Notion или Asana. Только заточена она под контент-задачи на основе данных о видимости бренда.
Каждая задача это карточка, которая проходит путь по воронке статусов: «Идея», «Бэклог», «В работе», «На ревью», «Готово». Внутри карточки лежит весь контекст для работы. Почему она вообще появилась, какие данные её обосновывают, рекомендованные источники, готовый план, текст статьи и ссылка на публикацию.
Контент-менеджеру больше не нужно придумывать тему с нуля и собирать под неё обоснование. Карточка приходит уже с аналитикой и черновиком плана, и человек сразу переходит к исполнению.
15 AI-агентов вместо ежедневного поиска в графиках
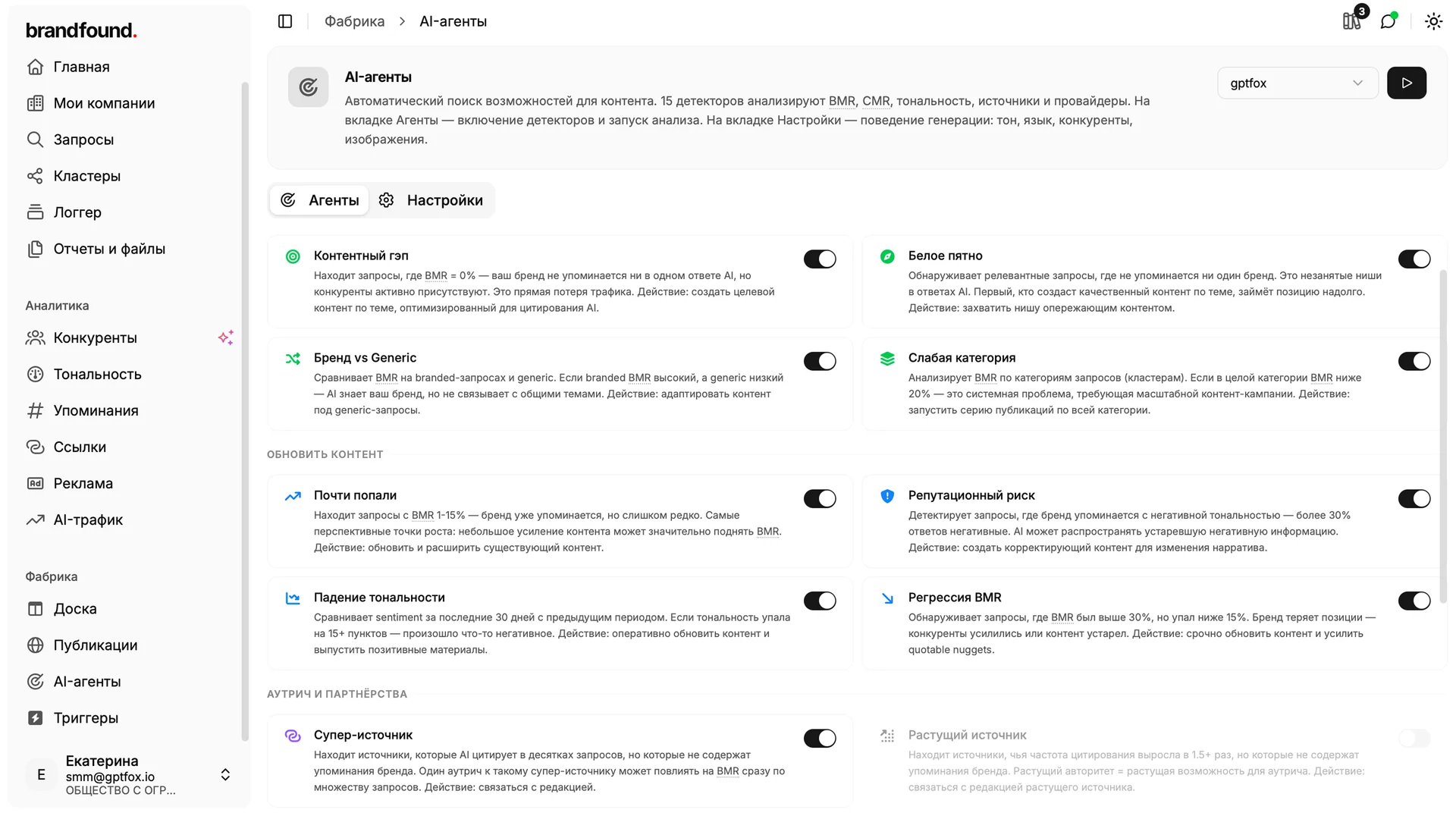
Карточки на доску заводят 15 AI-агентов. Это аналитические помощники, и каждый отвечает за свой паттерн.
-
Один следит за упоминаемостью бренда и замечает, когда он начинает проседать.
-
Другой ловит контентные гэпы, темы, где нейросети про вас молчат, хотя должны бы говорить.
-
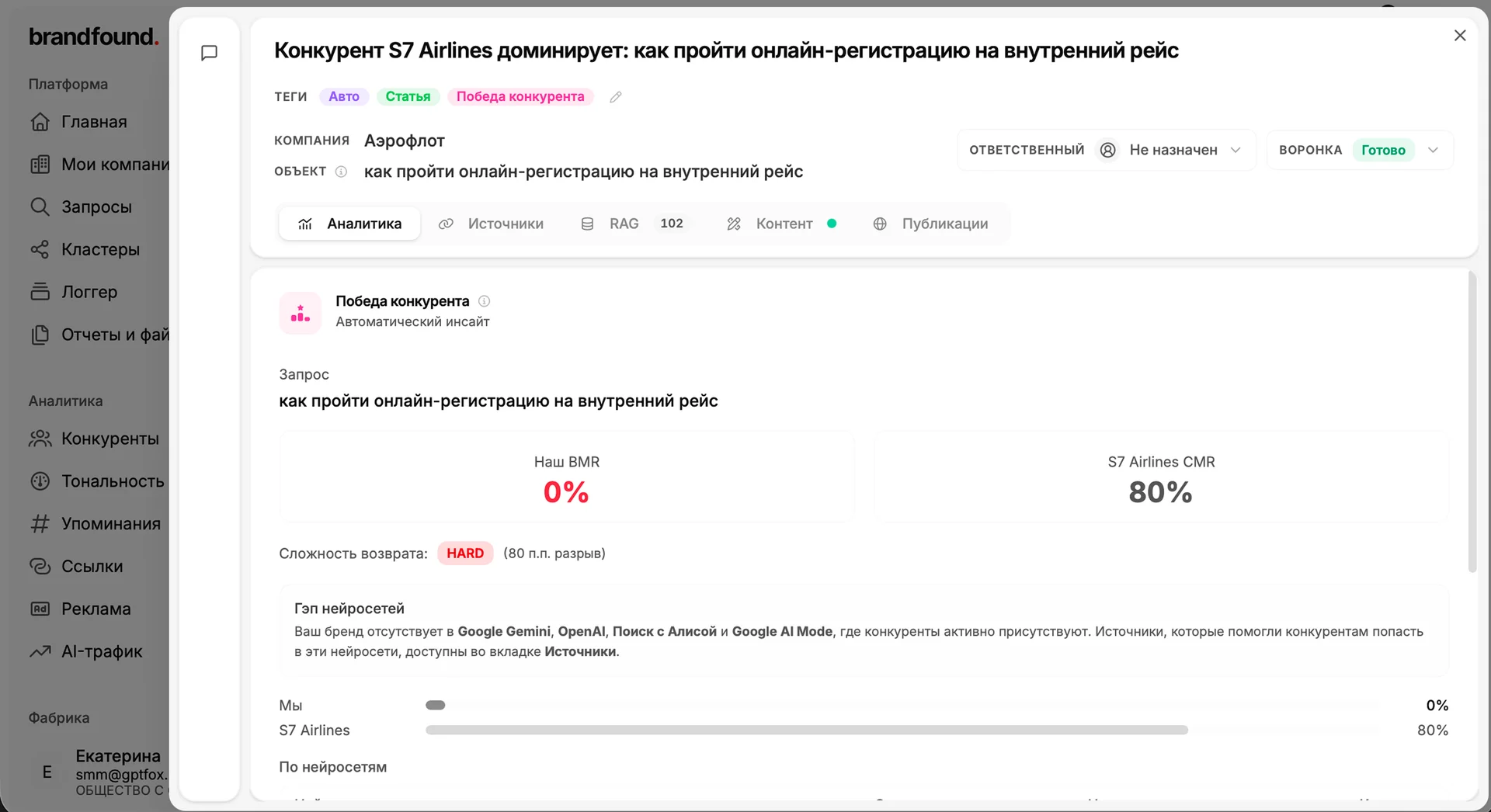
Третий отслеживает победы конкурентов, моменты, когда AI начинает чаще советовать кого-то другого вместо вас.
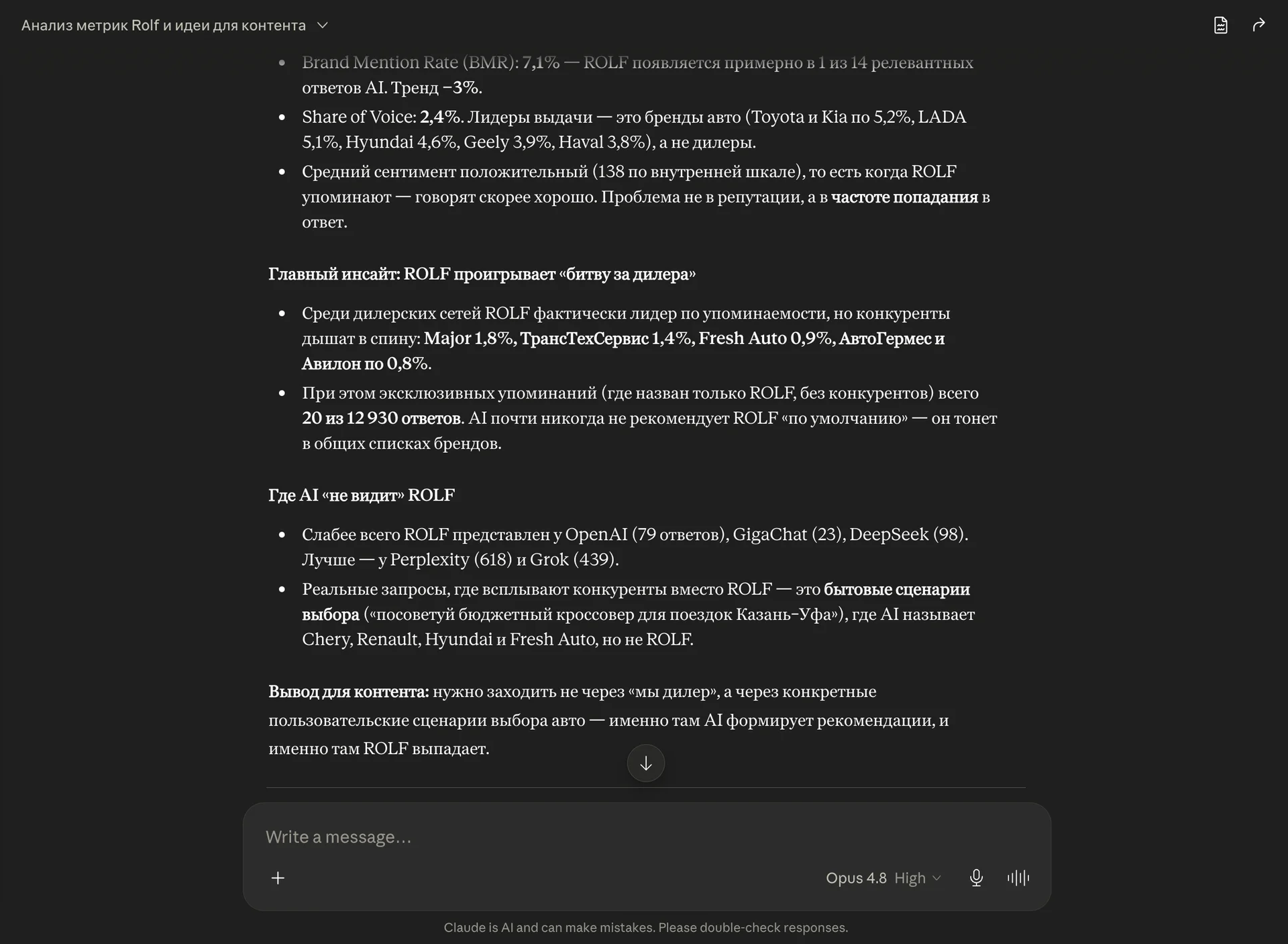
Ещё есть агенты по тональности, репутационному риску, слабым категориям, снижению цитируемости. Каждые 30 минут весь набор агентов проходит по вашей аналитике и по RAG-базе, ищет инсайты и выкатывает их карточками на доску.
Агент не просто сообщает, что у вас проблема, а сразу предлагает решение: конкретную контент-задачу с обоснованием и черновиком плана. Это превращает фабрику из генератора по запросу в проактивный инструмент, который сам подсказывает, что писать. Не нужно вручную листать дашборды, достаточно открыть доску и посмотреть, что нового. Каждого агента можно включить или выключить отдельно.
Как фабрика собирает статью - сквозной пример
Чтобы было понятно, как это выглядит на практике, разберём по шагам.
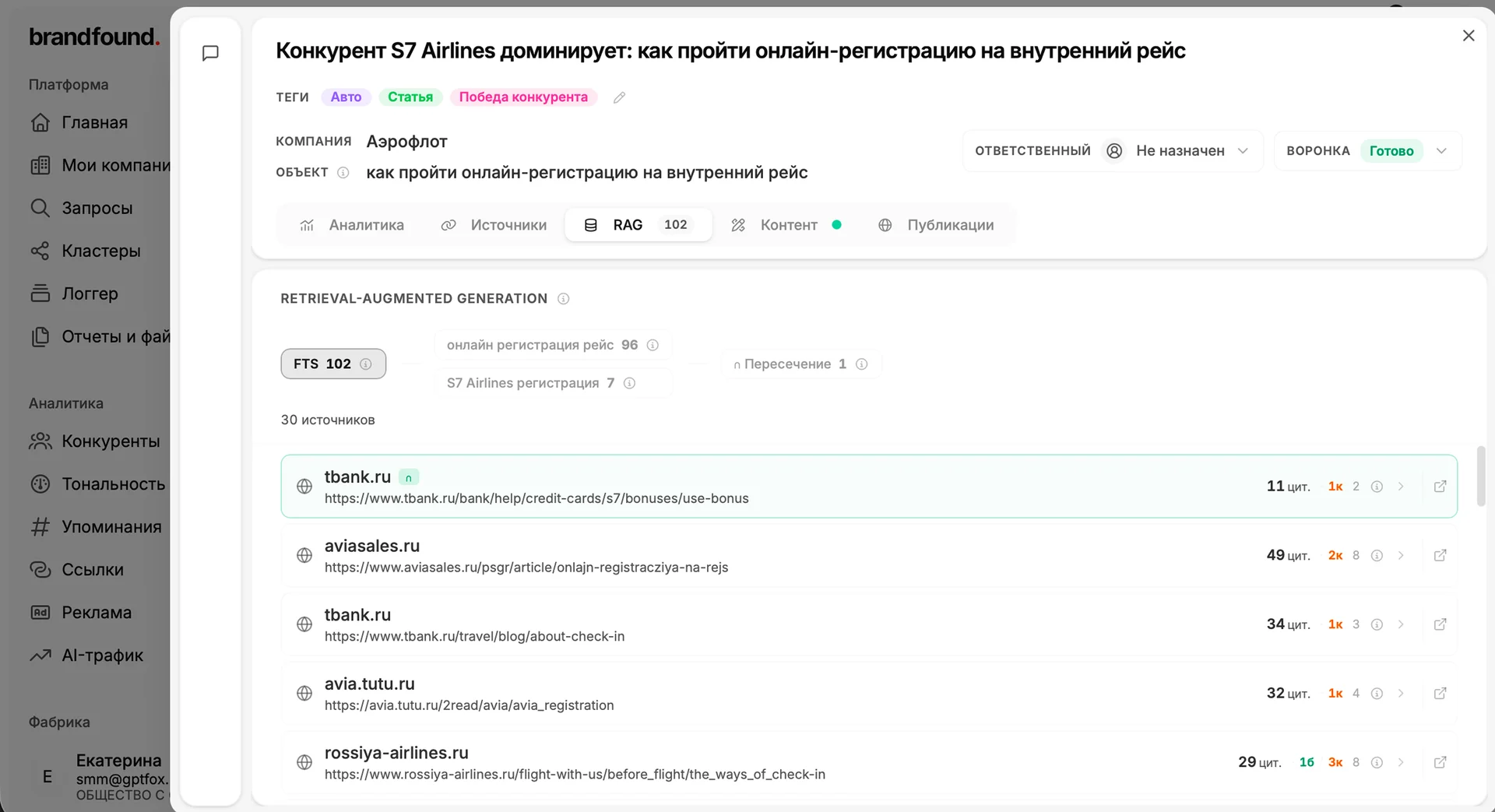 Допустим, агент замечает, что по одному из ваших продуктов в ответах нейросетей падает интерес, а конкурент по той же теме, наоборот, набирает упоминания. Агент не просто сигналит об этом. Он заглядывает в RAG-базу, находит, что в статьях про этот продукт упускается важная деталь, и кладёт на доску карточку с готовой темой и обоснованием.
Допустим, агент замечает, что по одному из ваших продуктов в ответах нейросетей падает интерес, а конкурент по той же теме, наоборот, набирает упоминания. Агент не просто сигналит об этом. Он заглядывает в RAG-базу, находит, что в статьях про этот продукт упускается важная деталь, и кладёт на доску карточку с готовой темой и обоснованием.
Вы открываете карточку и запускаете подготовку плана. Фабрика идёт не в общую память нейросети, а в вашу базу спарсенного контента. На реальном примере из демо это выглядело так: по теме набралось больше пятисот фрагментов текста из источников, которые нейросети цитируют. Фабрика прогоняет их через своего рода сито и оставляет полтора-два десятка по-настоящему релевантных пересечений. Уже на них строится контент-план.
 Дальше из плана генерируется статья, причём в реальном времени, прямо на ваших глазах. По ходу фабрика сама определяет конкурентов, расставляет акценты и помечает места, которые стоит проверить. В готовый текст автоматически подставляются промты для иллюстраций. Остаётся пройтись по подсвеченным точкам, и материал готов к публикации.
Дальше из плана генерируется статья, причём в реальном времени, прямо на ваших глазах. По ходу фабрика сама определяет конкурентов, расставляет акценты и помечает места, которые стоит проверить. В готовый текст автоматически подставляются промты для иллюстраций. Остаётся пройтись по подсвеченным точкам, и материал готов к публикации.
Настройки: статья звучит голосом вашего бренда
 Фабрика не выдаёт обезличенный текст. Перед генерацией вы задаёте рамки, и она их соблюдает.
Фабрика не выдаёт обезличенный текст. Перед генерацией вы задаёте рамки, и она их соблюдает.
Можно задать голос бренда, чтобы статья звучала именно так, как принято у вас, а не усреднённо. Настраивается конкурентная стратегия, активная или нейтральная, то есть насколько прямо в материале упоминаются и сравниваются конкуренты. Есть настройки самого контента: длина статьи, наличие блоков с мнением, примеров, таблиц. Есть гео-настройки, можно собирать материал под конкретный регион. Можно загрузить описание аудитории, чтобы текст попадал в неё точнее.
Отдельно стоит сказать про блок «Мнение эксперта», он включён по умолчанию.
Нейросети охотнее цитируют экспертный контент, цитаты специалистов, развёрнутые комментарии, оценки. Поэтому фабрика добавляет в статью блок с экспертным мнением. Это один из приёмов, которые мы вывели, наблюдая за тем, что нейросети реально забирают в свои ответы.
Answer Capsule: маленький блок, который повышает цитируемость
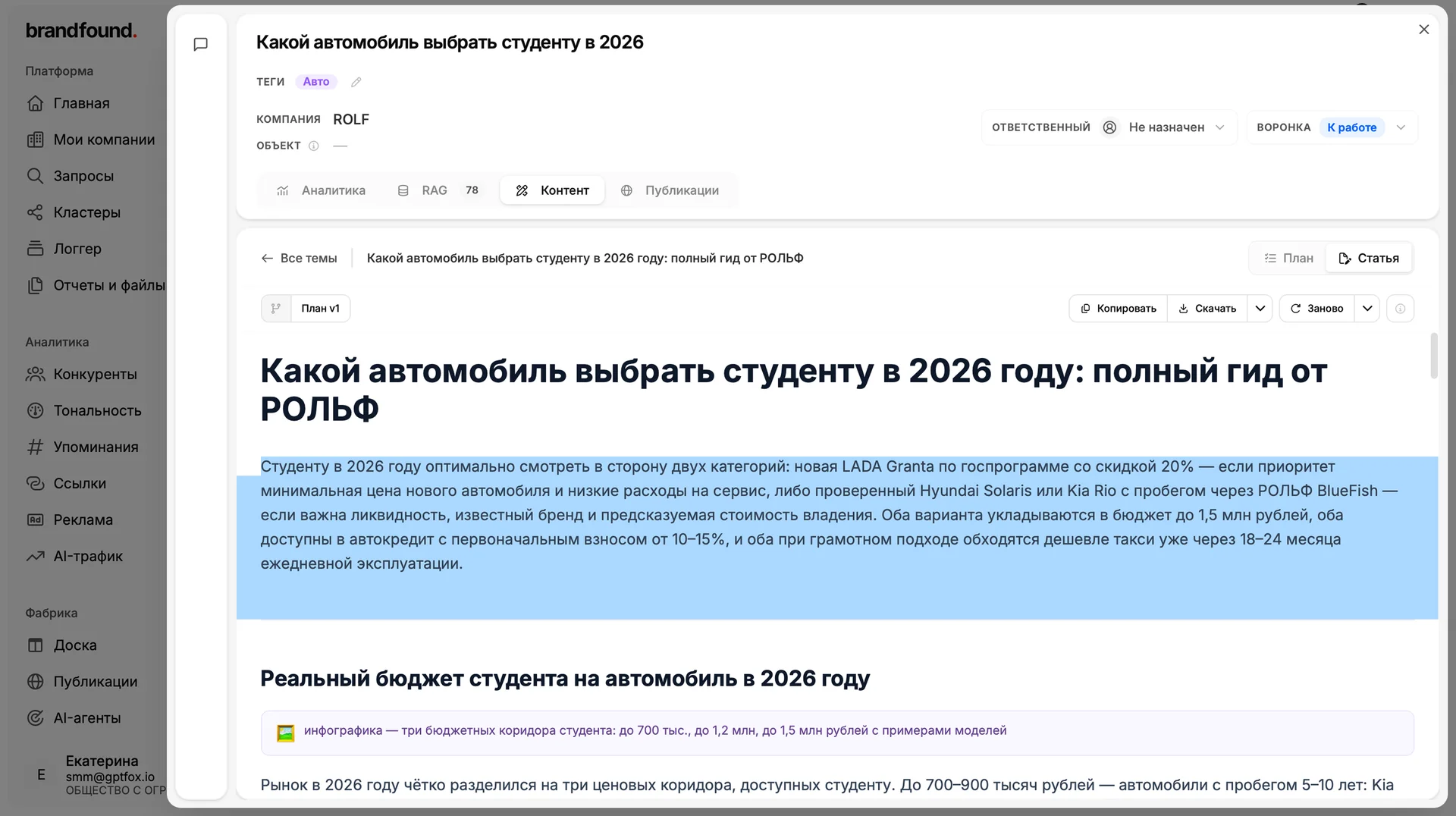 В начало каждой статьи фабрика автоматически вставляет Answer Capsule, короткий блок-ответ в первых строках. Это сжатый тезис, который нейросеть может забрать в свою выдачу целиком.
В начало каждой статьи фабрика автоматически вставляет Answer Capsule, короткий блок-ответ в первых строках. Это сжатый тезис, который нейросеть может забрать в свою выдачу целиком.
Приём не выдуман: мы вычислили его эмпирически, наблюдая за тем, какие именно фрагменты статей нейросети чаще всего цитируют. Короткий, конкретный ответ без воды в самом начале материала попадает в выдачу заметно чаще, чем та же мысль, размазанная по тексту. В фабрике вам не нужно об этом думать, капсула формируется сама.
Одна новость, много углов
Когда у бренда выходит новость, писать одну статью «у нас вышел продукт» неэффективно. Фабрика берёт один контекст и автоматически раскладывает его на разные типы контента: кейс, сравнение, исследование, мнение, факт, гайд, разбор, подборка, how-to. Получается до 11-ти разных подходов к одной теме.
Смысл в том, что каждый формат закрывает свой пользовательский интент. Кто-то ищет инструкцию, кто-то сравнение, кто-то экспертное мнение. Нейросети цитируют эти форматы по-разному, поэтому одна новость даёт сразу несколько слоёв охвата вместо одной банальной статьи. Это снимает с контент-менеджера вечную задачу «придумать новый формат».
RAG-база: почему статья получается фактически точной
RAG это разновидность баз данных, векторная. Нейросети сами устроены на этой же технологии, потому что векторная разметка позволяет искать не по точному совпадению слов, а по смыслу.
Для каждого аккаунта в brandfound разворачивается отдельное хранилище. Каждый раз, когда нейросеть в своём ответе ссылается на источник, наши парсеры идут на этот источник, выкачивают текст и складывают его фрагментами в вашу базу. Даже если статья там уже была, мы перепарсим её заново: нам важно отслеживать и поведение нейросети тоже, изменилось ли цитирование, какие фрагменты она теперь предпочитает.
Получается живая библиотека источников, на которые модель опирается при генерации плана и текста. Поэтому статья выходит не «про бренд вообще», а собранная из того, что нейросети уже реально цитируют в вашей нише. Это и есть принципиальная разница с лёгкими инструментами, которые просто шлют промт в чужую модель и не имеют под собой никаких ваших данных.
Встроенный фактчек: проверяете не всю статью, а пару точек
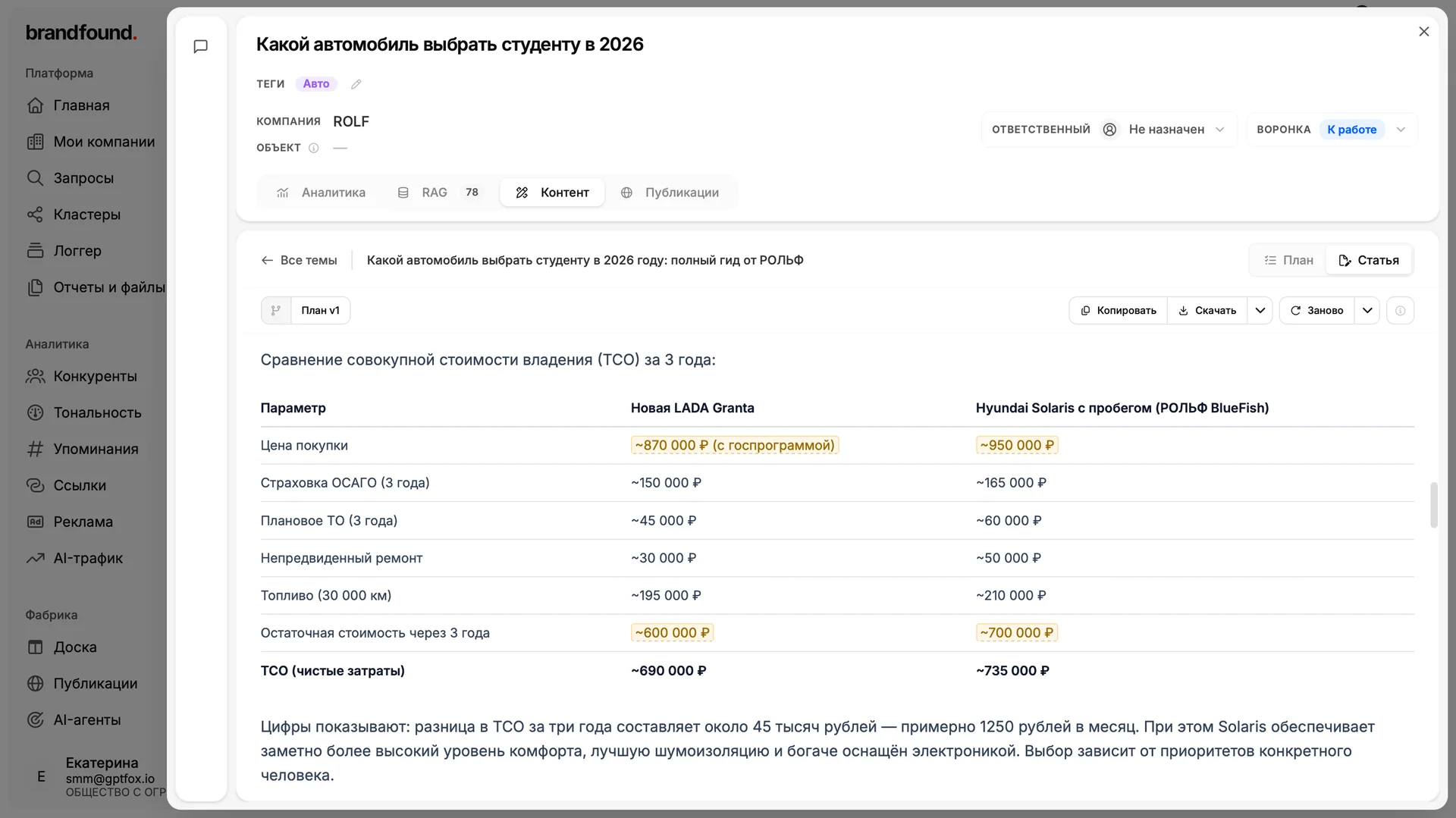 Многие команды опасаются публиковать AI-контент из-за неточных цифр. И опасение здесь не про галлюцинации, откровенных выдумок в фабрике мы практически не замечаем. Проблема именно в конкретике: сколько процентов, сколько штук, в каком году.
Многие команды опасаются публиковать AI-контент из-за неточных цифр. И опасение здесь не про галлюцинации, откровенных выдумок в фабрике мы практически не замечаем. Проблема именно в конкретике: сколько процентов, сколько штук, в каком году.
Поэтому в плане и в готовой статье фабрика сама подсвечивает жёлтым места, в которых не уверена. Вы проверяете не весь текст, а только эти точки, и это занимает минуту-другую вместо полной вычитки. Без такого встроенного фактчека ставить контент на поток нельзя, особенно крупным брендам, где материал проходит через юристов и согласования.
Триггеры: доска двигается сама
Чтобы карточки не приходилось перетаскивать вручную, в фабрике работают триггеры. Это правила, которые реагируют на события и сами двигают задачи по воронке. Простой пример, вы добавили в карточку ссылку на опубликованный материал, и она автоматически уехала в «Готово». Триггеры убирают рутину и держат доску в актуальном состоянии без ручного администрирования.
Цикл замыкается на результате, а не на «вот данные и больше ничего»
Самая продуктовая часть фабрики начинается после публикации. Когда статья вышла и ссылка добавлена в карточку, платформа отслеживает, через сколько дней материал впервые попал в ответы AI, как часто его потом цитируют и как это сдвинуло упоминаемость бренда.
Так замыкается полный цикл: аналитика, инсайт, план, статья, фактчек, публикация, замер, корректировка. Вы получаете KPI по видимости в нейросетях, а не по дочитываниям. По каждой единице контента видно её реальный эффект. На дашборде это выглядит предельно конкретно: одна статья за месяц принесла, условно, плюс почти две сотни упоминаний бренда, а другая пока ноль и требует доработки или перепродвижения. Материалы, которые сработали, получают приоритет в дальнейшем продвижении.
Для агентств это меняет сам разговор с клиентом. Отчёт строится не на «мы видим, что у вас просадка», а на «мы видели просадку, вот публикация, которая её закрыла, и вот цифры, как это сработало». У большинства сервисов цикл обрывается на «вот вам данные». У нас он доходит до закрытой задачи и измеримого результата.
Команда работает вместе
 Фабрика построена как CRM-канбан для контент-задач, поэтому в ней удобно работать командой. Коллег можно отмечать через @, назначать ответственных, фиксировать дедлайны. У плана есть версионирование, так что несколько человек могут редактировать его и переключаться между версиями. Внутри карточки есть чат, и вся переписка по задаче остаётся рядом с самой задачей, а не теряется в мессенджерах. По сути это аналог Notion или Asana, только каждая карточка приходит уже с аналитикой и черновиком, а не пустой.
Фабрика построена как CRM-канбан для контент-задач, поэтому в ней удобно работать командой. Коллег можно отмечать через @, назначать ответственных, фиксировать дедлайны. У плана есть версионирование, так что несколько человек могут редактировать его и переключаться между версиями. Внутри карточки есть чат, и вся переписка по задаче остаётся рядом с самой задачей, а не теряется в мессенджерах. По сути это аналог Notion или Asana, только каждая карточка приходит уже с аналитикой и черновиком, а не пустой.
Не только статьи: связка с MCP
Сама фабрика заточена под текстовые форматы: статья, факт, исследование, мнение, кейс, подборка, гайд. Сценарии для Reels и других вирусных форматов это отдельный жанр, который фабрика напрямую не делает. Но платформа на этом не замыкается.
 Через MCP-сервер данные brandfound доступны прямо в AI-инструментах, с которыми работает ваша команда. Можно, например, попросить ассистента проанализировать ваши метрики из brandfound и предложить сценарий для рилса. Он заберёт данные, при необходимости заглянет в тренды и выдаст темы и сценарии. То есть фабрика закрывает текстовый контент-конвейер, а связка с MCP добавляет к этому любой другой формат поверх тех же данных.
Через MCP-сервер данные brandfound доступны прямо в AI-инструментах, с которыми работает ваша команда. Можно, например, попросить ассистента проанализировать ваши метрики из brandfound и предложить сценарий для рилса. Он заберёт данные, при необходимости заглянет в тренды и выдаст темы и сценарии. То есть фабрика закрывает текстовый контент-конвейер, а связка с MCP добавляет к этому любой другой формат поверх тех же данных.
Кому это полезно
Контент-командам и агентствам. Тему больше не нужно придумывать. Она приходит на доску с обоснованием и планом, остаётся довести до публикации, а результат можно показать клиенту в цифрах.
Маркетинговым директорам и бренд-менеджерам. Видно отдачу каждой статьи в упоминаниях бренда, а не в абстрактных просмотрах. Особенно полезно брендам с акцентом на медийную коммуникацию: репутация, доля голоса, присутствие в ответах нейросетей.
PR-командам и тем, кто проходит согласования. Встроенный фактчек снимает страх перед неточными цифрами в AI-тексте и делает публикацию AI-контента управляемой.
Готовая статья доступна сразу в нескольких форматах: Markdown, чистый текст и HTML с корректной разметкой, причём служебные элементы в финальной версии вычищаются. Можно скопировать материал и вставить прямо в редактор вашего блога или CMS.


